

はじめに
自分がメインとして使っている言語はC#なのですが、今回Pythonの知識も必要になったので学習してみました。
この記事は「この方法が最善だった!」というのではなく、どういう方針で何をしたかを記していきます。
主にやったことは3種類で、
- 本を読む
- チュートリアルをやる
- 競技プログラミングをやる
をしました。
本当は実際にアプリを作ったりした方が勉強になると思っていたのですが、作りたい物が思いつかずとりあえず手を動かせる競プロにしました。
それでは各章ごとに解説していきます。
1. 本を読む
今回読んだ本は絵本シリーズのものを読みました。
これは単純に私が絵本シリーズが好きで、たまたま持っていたPythonの本がこれだけなので読みました。
Pythonの絵本 Pythonを楽しく学ぶ9つの扉 | 株式会社アンク |本 | 通販 | Amazon
このシリーズはイラストが多く、文量も少ないため気楽に読めます。
しかし対象読者は完全初心者向けなので経験者には物足りないかもしれません。
自分としては、構文などを忘れてしまった時にパッと確認できる点がいいかなと思いました。
本を読んで分かったことは、理解はできたけど全く身についてないことでした。
やはり実際にプログラムを組み立ててみないと感覚が掴めませんね。
2. チュートリアルをやる
そこで実際に作るのがいいと思ったのですが作りたいものが思いつきませんでした。
なのでとりあえず手を動かせるチュートリアル系を探しました。
2.1 アルゴ式
こちらのプログラミングサイトでは問題が出されてそれに答えていくような形式で勉強ができます。
しかし、自分は後述の理由で途中で辞めてしまいました。
トピック一覧 | アルゴ式
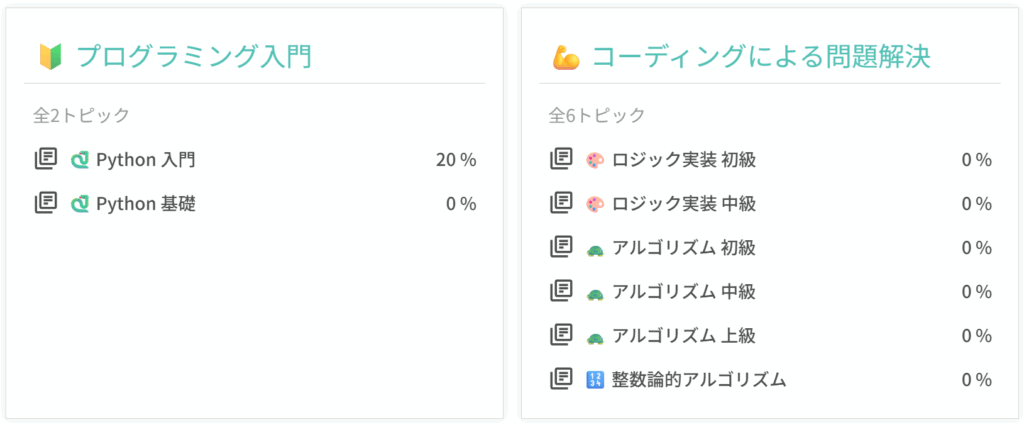
問題が出されて、それに対応したプログラムを提出するといった感じです。
実際にWeb上で実行できる点が良かったです、プログラムを書いている感じがしました。
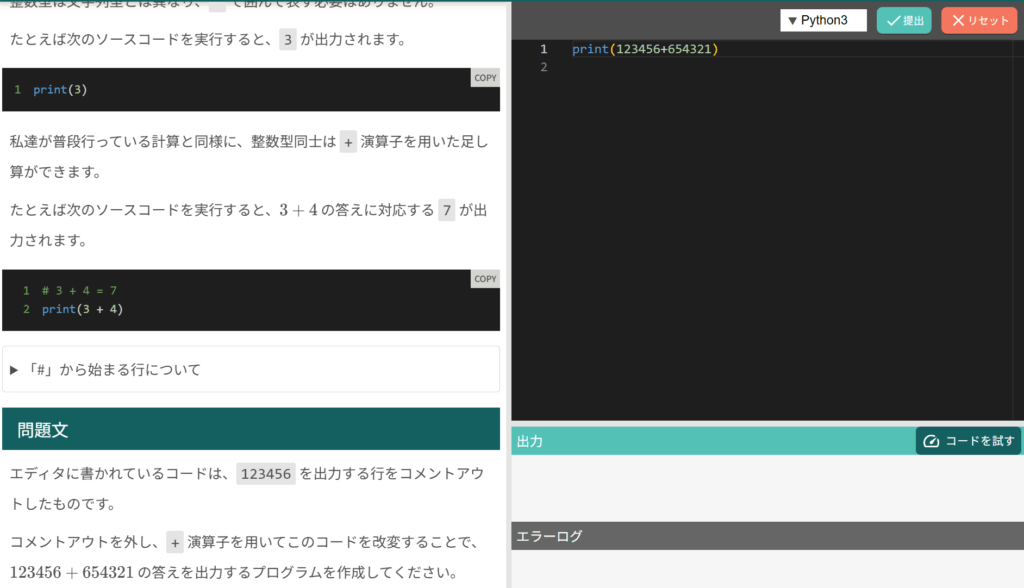
欠点としては、簡単すぎる点と記述式問題が場合がある点です。
短い解説で書かれている構文をそのまま書くだけなので写経とほぼ変わりません。
また自分の頭の中でプログラムを実行するというあまり本質的でない点も求められて、「やる意味あるのかなぁ」と感じました。
2.2 APG4bPython
こちらはAtCoder社が公開している教材です。
入門教材でありながら読みごたえがあり最後まで学習しました。
Python入門 AtCoder Programming Guide for beginners (APG4bPython) – AtCoder
こちらは前教材に比べ1ページの量が多く、基礎的な内容から応用的なTipsなど読んでいて退屈さを感じませんでした。
また同じくページごとに問題が用意されているのですが程よい難易度で、1ページの範囲が広いのでよく読みこむ必要があります。
欠点としては、アプリ開発というより競技プログラミングに寄った内容になっていることですね。
例えば、よく使う入力の受け方を構文として覚えるなどがあります。
a, b, c = map(int, input().split())
# 入力から 1 行読み取り、空白で区切って整数のリストを作る
a = list(map(int, input().split()))実際にプログラムを書いていてこのような形式のデータや入力方式を使ったことはないので限定的ではありますね。
ですが今回に限っては、この後競プロでPythonに慣れようと思っていたので自分にとっては良い点でもありました。
この教材は一番やって良かったことだったと思います。
学習したことをまとめておきます。(本文抜き出し)
他言語からPythonに移行する人には参考になる箇所かもしれません。
勉強になった点
1.03.四則演算と優先順位
発展的な内容
負の除数による除算
競技プログラミングでは敢えて除数を負にする必要があるケースはあまり見かけませんが、思わぬ罠になる可能性があるので、プログラムの挙動について説明しておきます。
a を b で割った商を q 、余りを r とします。 b が正のときは a=b×q+r (0≤r<b) が成立すると説明しましたが、除数 b が負のときは余りの範囲も負の方向になり、 a=b×q+r (b<r≤0) を満たすように商・余りが決まります。
11=(−5)×(−3)+(−4) より、11 を −5 で割った商は −3 、余りは −4 となります。
−11=(−5)×2+(−1) より、−11 を −5 で割った商は 2 、余りは −1 となります。
print(11 // -5)
print(11 % -5)
print(-11 // -5)
print(-11 % -5)実行結果
-3
-4
2
-1divmod
a を b で割った商は a // b 、余りは a % b で取得できることは既に学びましたが、 divmod 関数を使うことでこれらを同時に取得することもできます。
具体的には、 divmod(a, b) で a を b で割った商と余りのタプルを返します。「タプル」についてはまだ扱っていないので詳細は省略しますが、次のようなコードで取得できることを覚えておけば十分です。
q, r = divmod(20, 7)
print(q)
print(r)実行結果
2
61.04.変数と型
指数表記
float 型では指数表記による記述もできます。絶対値が大きいまたは小さい数の場合は、 print 関数で出力した結果も指数表記になります。
x = 1.23e5
y = 3.5e-2
z = 2.7e-10
print(x)
print(y)
print(z)実行結果
123000.0
0.035
2.7e-10複数の変数への代入
変数 x に 2 を、変数 y に 3 を代入するという操作を同時に行いたいときは、カンマ(,)で区切って次のように書くことができます。
x, y = 2, 3
print(x)
print(y)実行結果
2
3これを使うと、 x と y の値を入れ替える(Swap する)という操作も簡単に書くことができます。
x = 2
y = 3
x, y = y, x # x と y を入れ替える
print(x)
print(y)実行結果
3
2発展的な内容
int 型同士のべき乗
a と b がともに int 型のとき、 a ** b の型はどうなるでしょうか。簡単のため a はゼロではないとします。
この場合は b≥0 の場合は int 型、 b<0 の場合は float 型になります。
print(2 ** 3)
print(2 ** -3)実行結果
8
0.1251.05.入力
入力の受け取り方
空白区切りの入力
前述のように、input() は 1 行の入力を文字列として受け取ります。
そこで、次のプログラムのように input() で受け取った文字列を split() で空白区切りで分解することで別々の変数に格納することができます。
a, b, c = input().split()
print(a)
print(b)
print(c)入力
10 20 30実行結果
10
20
30このままだと文字列として扱っていますが、次のプログラムのように int() を使って整数に変換することもできます。
a, b, c = map(int, input().split())
print(a * 10)
print(b * 100)
print(c * 1000)入力
10 20 30実行結果
100
2000
30000また、split() は以下のように区切り文字を指定することもできます。
これまでのように何も指定しない場合は、空白文字で区切られます。
a, b, c = input().split(":")
print(a)
print(b)
print(c)入力
10:20:30実行結果
10
20
301.06.if文・比較演算子・論理演算子
キーポイント
if文を使うと、「指定した条件に当てはまるときだけ処理をする」というプログラムを書けるelifやelseを使うと、「条件に当てはまらなかったとき」の処理を書ける
if 条件式1:
処理1 (条件式1に当てはまるときに実行)
elif 条件式2:
処理2 (条件式1に当てはまらず、条件式2に当てはまるときに実行)
else:
処理3 (条件式1にも条件式2にも当てはまらないときに実行)- 一般的な論理演算子のまとめ
| 演算子 | 意味 | 真になるとき |
|---|---|---|
not 条件式 | 条件式 の真偽の反転 | 条件式 が偽 |
条件式1 and 条件式2 | 「条件式1 が真」かつ「条件式2 が真」 | 条件式1 と 条件式2 のどちらも真 |
条件式1 or 条件式2 | 「条件式1 が真」または「条件式2 が真」 | 条件式1 と 条件式2 の少なくとも片方が真 |
比較演算子の連鎖
上のプログラムの 0 <= x and x <= 100 の部分を、Python では次のプログラムのように 0 <= x <= 100 と書くこともできます。
x = int(input())
if 0 <= x <= 100:
print("x は 0 以上 100 以下です")
else:
print("x は 0 以上 100 以下ではありません")また、a < b < c < d のように 3 つ以上繋げて書いたり、a < b > c のように異なる演算子についても繋げて書くことができます(a < b > c は a < b and b > c と同じ意味です)。
💡 ちなみに
この書き方は、あまり濫用するとかえってわかりづらくなってしまうので注意が必要です。例えば、a != b != c と書いたとき、これは a != b and b != c と同じ意味なので、a と c が異なるかどうかを判定していません。
1.07.論理式の値とbool型
bool 型
他の型からの変換
キャストは数値以外でも行われます。代表的な例を次の表に記載します:
| 型 | 変換ルール | True となる例 | False となる例 |
|---|---|---|---|
数値 (int, float) | 値が0と等しいときのみ False | 1, 0.01, -1e18 | 0, 0.0 |
| 文字列 | 空文字列 "" のときのみ False | "hoge", "A", " " | "" |
| 配列 | 配列が空 (長さが 0) のときのみ False | [1,2,3], ["foo"], [0] | [] |
1.08.while文
応用例
N 人の合計点を求めるプログラムを作ってみましょう。
次のプログラムは「入力の個数 N」と「点数を表す N 個の整数」を入力で受け取り、点数の合計を出力します。
N = int(input())
s = 0 # 合計点を表す変数
i = 0 # カウンタ変数
while i < N:
x = int(input())
s += x
i += 1
print(s)入力
3
1
10
100実行結果
1111.09.for文・break・continue
キーポイント
- for 文は繰り返し処理でよくあるパターンを while 文より短く書くための構文
- 列の中身が順に変数に代入される
for 変数 in 列:
処理- N 回の繰り返し処理は以下の for 文で書くのが一般的
for i in range(N):
処理N 回の繰り返し処理
range(a, b) の a は 0 のときに省略することができ、range(b) と書くことができます。よって、次の二つの書き方は同じ意味になります。
for i in range(0, 5):
print(i)
for i in range(5):
print(i)細かい話
2 ずつ増やす
上では range(a, b) という書き方のみ紹介しましたが、実は range(a, b, c) という書き方もできこれによりいくつずつ増やすかを決めることができます(c を省略したときのデフォルトは 1 なので、これまでの書き方では全て 1 ずつ増えていました)。
よって、次のように書くことで 2 ずつ増やすことができます。
for i in range(0, 10, 2):
print(i)実行結果
0
2
4
6
8for-else, while-else
Python では for 文と while 文に else 節を書くことができます。
これは、ループが break 文で終了した場合は実行されず、そうでないとき(ループが最後まで回ったとき)に実行されます。
break しない場合
for i in range(5):
print(i)
else:
print("ループが最後まで回りました。")
print("終了")実行結果
0
1
2
3
4
ループが最後まで回りました。
終了break する場合
for i in range(5):
if i == 3:
print("ぬける")
break # i == 3 の時点でループから抜ける
print(i)
else:
print("ループが最後まで回りました。")
print("終了")実行結果
0
1
2
ぬける
終了1.10.リスト
リストの長さ
- リスト a に対し、
len(a)で a の長さ(要素数)を取得できます。
入力からリストを作る
- 文字列 s に対し、
s.split()で s を空白で区切って文字列のリストを作ることができます。 - 文字列のリスト a に対し、
list(map(int, a))で a の各要素を整数に変換したリストを作ることができます。 list(map(int, input().split()))で、入力から 1 行読み取り、空白で区切って整数のリストを作ることができます。
# 入力から 1 行読み取り、空白で区切って整数のリストを作る
a = list(map(int, input().split()))
print(a)入力
886 551 37 424 531出力
[886, 551, 37, 424, 531]リストを出力する
- リスト a に対し、
print(*a)で a の要素を空白区切りで出力できます。
a = [9, 9, 7, 3]
# a の要素を空白区切りで出力する
print(*a)
# a の要素を改行区切りで出力する
for x in a:
print(x)出力
9 9 7 3
9
9
7
3リストのさらなる機能
負の添字
- リスト a と負の整数 i に対し、
a[i]で a の 後ろから −i−1 番目の要素を取得することができます。末尾の要素はa[-1]で、先頭の要素はa[-len(a)]で取得することができます。
リストをつなげる
- リスト a とリスト b に対し、
a + bで a と b をつなげたリストを作ることができます。 - リスト a と整数 n に対し、
a * nで a を n 回繰り返したリストを作ることができます。
# リスト [1, 6] とリスト [1, 8] をつなげて [1, 6, 1, 8] を作り、a に代入する
a = [1, 6] + [1, 8]
# [1, 6, 1, 8] に [0, 3, 3] をつなげて [1, 6, 1, 8, 0, 3, 3] とする
a += [0, 3, 3]
# リスト [0, 1, 2] を 3 回繰り返したリスト [0, 1, 2, 0, 1, 2, 0, 1, 2] を作り、a に代入する
a = [0, 1, 2] * 3リストの末尾に要素を追加・削除する
- リスト a と値 x に対し、
a.append(x)で a の末尾に要素 x を追加できます。 - リスト a に対し、
a.pop()で a の末尾の要素を取得しながら削除できます。
# 空のリストを作り、a に代入する
a = []
# a の末尾に 1 を追加する。a は [1] になる。
a.append(1)
# a の末尾に 2 を追加する。a は [1, 2] になる。
a.append(2)
# a の末尾に 3 を追加する。a は [1, 2, 3] になる。
a.append(3)
# a の末尾の要素 3 を出力し、削除する。a は [1, 2] になる。
print(a.pop())
# a の末尾の要素 2 を出力し、削除する。a は [1] になる。
print(a.pop())
# a の末尾の要素 1 を出力し、削除する。a は [] になる。
print(a.pop())リストの好きな位置に要素を追加・削除する
- リスト a と整数 i と値 x に対し、
a.insert(i, x)で a の i 番目の位置 (a[i-1]とa[i]の間) に x を挿入することができます。 - リスト a と整数 i に対し、
a.pop(i)で a の i 番目の要素を取得しながら削除することができます。
リストの途中への挿入・削除は、それ以降の要素をずらす必要があるため、末尾への挿入・削除と比べて時間がかかります。
リストの中に x があるか調べる
- リスト a と値 x に対し、
x in aで x が a の中に 1 個以上存在するかを判定することができます。not (x in a)はx not in aと書くこともできます。
- リスト a と値 x に対し、
a.count(x)で x が a の中に何個存在するかを取得することができます。 - リスト a と値 x に対し、
a.index(x)で a の中に x が出現する最初の位置を取得することができます。
# x が 1, 2, 3 のいずれかであるかを判定する
x = 2
print(x in [1, 2, 3])
a = [3, 1, 4, 1, 5]
# a の中に存在する 1 の数 (2 個) を数える
print(a.count(1))
# a の中に存在する最初の 1 の位置 (a[1]) を調べる
print(a.index(1))出力
True
2
1リストをソートする
- リスト a に対し、
a.sort()で a の要素を昇順に並べ替えることができます。
リストを反転する
- リスト a に対し、
a.reverse()で a の要素を逆順に並べ替えることができます。
リストを複製する
リスト a に対し b = a とすると、リストは複製されず、a の指すリストと b の指すリストは同一のものになります。
これを回避するには、b = a.copy() と書いて、リストを複製する必要があります。
リストの一部分を複製する(スライス)
- リスト a と整数 l,r (0≤l≤r≤len(a)) に対し、
a[l:r]で a[l] から a[r−1] までの r−l 要素からなるリストを作ることができます。
a = [3, 1, 4, 1, 5]
# a[1] から a[3] までの 3 要素からなるリストを作る
print(a[1:4])
# a[0] から a[4] までの 5 要素からなるリストを作る
print(a[0:5])出力
[1, 4, 1]
[3, 1, 4, 1, 5]a = [3, 1, 4, 1, 5, 9]
# a[0:6] を作る (リストを複製する)
print(a[:])
# a[0:6] から 2 要素ごとに取り出したリストを作る
print(a[::2])
# a[1:6] から 2 要素ごとに取り出したリストを作る
print(a[1::2])
# a[1:5] から 3 要素ごとに取り出したリストを作る
print(a[1:5:3])出力
[3, 1, 4, 1, 5, 9]
[3, 4, 5]
[1, 1, 9]
[1, 5]リストを比較する
- リスト a,b に対し、
a == b/a != bでリストの全要素が一致しているかを判定することができます。 - リスト a,b に対し、
a < b/a <= b/a > b/a >= bで a と b を辞書式順序で比較できます。
1.11.文字列
キーポイント
- 文字列は変更不可能。一部を変更したいときは、文字のリストを作る
for 文で文字列の中の文字を列挙する
- 文字列 s に対し、
for x in s:で s の中の文字を順に x に代入して繰り返し処理を行うことができます。
s = "AtCoder"
for x in s:
print(x)出力
A
t
C
o
d
e
r文字列を整数に変換する
- 文字列 s に対し、
int(s)で s を整数に変換することができます。
整数を文字列に変換する
- 整数 x に対し、
str(x)で x を文字列に変換することができます。
# 999999999999999999999999999999 + 1 を出力
print(int("9" * 30) + 1)
# 3 ** 1000 の桁数を出力
print(len(str(3 ** 1000)))出力
1000000000000000000000000000000
478整数・文字列変換における桁数制限
整数から文字列への変換、文字列から整数への変換において、変換に時間がかかることを防ぐため、4300 桁よりも大きな数は変換できないようになっています。整数を出力するときにも整数から文字列への変換が行われるので、この制限が適用されます。sys.set_int_max_str_digits(0) を実行することで、この制限を取り除くことができます。
文字列のリストを連結する
- 文字列 s と文字列のリスト a に対し、
s.join(a)で s を区切り文字列として a の各要素を連結することができます。
# "1 23 456" を空白文字で区切り、リスト ["1", "23", "456"] を作る
a = "1 23 456".split()
# ["1", "23", "456"] を文字列 " + " で結合してできる文字列 "1 + 23 + 456" を出力する
print(" + ".join(a))出力
1 + 23 + 456部分文字列に x があるか調べる
- 文字列 s,t に対し、
t in sで s の部分文字列に t が含まれるかどうか判定することができます。 - 文字列 s,t に対し、
s.index(t)で s に現れる最初の部分文字列 t の位置を求めることができます。 - 文字列 s,t に対し、
s.count(t)で s に部分文字列 t が重ならずに何回出現するかを求めることができます。
# 文字列 "ABABABA" を作り s に代入する
s = "ABABABA"
# "ABABABA" の部分文字列に "BAB" があるか判定する
print("BAB" in s)
# "ABABABA" に現れる最初の部分文字列 "BAB" の位置を求める
# s[1:4] が最初の "BAB" なので、1 を出力する
print(s.index("BAB"))
# "ABABABA" に重ならずに現れる部分文字列 "BAB" の個数を求める
# s[1:4] と s[3:6] が "BAB" であるが、重ならずに取れるのは 1 個までなので、1 を出力する
print(s.count("BAB"))
# "AAAAAAAAAA" (A が 10 個) から重ならずに取れる "AAA" は 3 個まで
print("AAAAAAAAAA".count("AAA"))出力
True
1
1
3数字かどうか判定する
- 文字列 s に対し、
s.isdigit()で s が空でなく、s の文字がすべて数字かどうか判定することができます。
文字列の一部を変更する
Python の文字列は 一度作ると変更することができません。 文字列の一部を変更したい場合は、一度文字のリストに変換する必要があります。
# 文字列 "AtCoder" を作り s に代入する
s = "AtCoder"
# s は for 文に入れられるものであるから、list(s) で
# リスト ["A", "t", "C", "o", "d", "e", "r"] を作れる
a = list(s)
# a の 0 番目の要素を "M" に変更する
a[0] = "M"
# a の要素をつなげて出力する
print("".join(a))出力
MtCoder文字
Python では、1 つの文字は長さ 1 の文字列として str 型で表現されます。 したがって、文字列から取り出した「文字」に対しても文字列に対するさまざまな機能を使うことができます。
# 文字列 "0123456789" の 0 番目の文字 "0" を c に代入
c = "0123456789"[0]
# c は長さ 1 の文字列である
print(len(c))
# c.isdigit() で "0" が数字であるか判定する
print(c.isdigit())
# int(c) で整数に変換できる
print(int(c))出力
1
True1.12.組み込み関数
Python 標準の関数
abs
pow
pow(a,b) で a の b 乗の値を計算します。pow(a,b,mod) で a の b 乗を mod で割った余りを計算します。
a = 3
b = 4
mod = 10
res = pow(a, b)
res2 = pow(a, b, mod)
print(res, res2)実行結果
81 1min max
与えられた2つ以上の数値の中の最小値, 最大値を計算して返します。
min_val = min(1, 3, -5, 2)
max_val = max(1, 3, -5, 2)
print(min_val, max_val)実行結果
-5 3数値をリストとして与えることも可能です。
l = [1, 3, -5, 2]
min_val = min(l)
max_val = max(l)
print(min_val, max_val)実行結果
-5 3sum
sorted
リストをソートし、新たなリストを返します。
1.10 節で扱った l.sort() と異なり、元のリストはソートされていない点に注意してください。
all any
all は与えられたリストの要素すべてが条件式として真であるかを判定します。any は与えられたリストの要素の中に条件式として真であるものが1つ以上存在するかを判定します。
l = [1, 3, -5, 2]
res = all([v>0 for v in l]) # l に含まれる値が全て正か?
res2 = any([v%2==0 for v in l]) # l に偶数が含まれるか?
print(res, res2)実行結果
False Trueなお、空のリストに対して all は True を、any は False を返します。
print(all([]), any([]))実行結果
True Falseenumerate
for i,v in enumerate(リスト): のように書くことでリストのインデックスと値を同時に取得することができます。
l = [1, 3, -5, 2]
for i,v in enumerate(l):
print(i, "番目の要素は", v, "です")実行結果
0 番目の要素は 1 です
1 番目の要素は 3 です
2 番目の要素は -5 です
3 番目の要素は 2 です次のように書いても同一の結果になりますが、enumerate を使うほうが単純に記述することができます。
l = [1, 3, -5, 2]
for i in range(len(l)):
v = l[i]
print(i, "番目の要素は", v, "です") 1.13.関数
関数内の変数
一方で、関数の外の変数は自由に使用することが可能です。以下は、変数aの値をプリントするprint_a関数を用いた例です。
a = 0
def print_a():
print(a)
print_a() # 0 が表示される
a = 1
print_a() # 1 が表示される変数aは関数の外で宣言されていますが、その値をprint_a関数の内部で用いることができていることが分かります。これは、変数aのスコープがグローバル(つまり、コード全体)であるためです。このような変数のことをグローバル変数と呼びます。
一方で、関数内でグローバル変数を変更する場合には注意が必要です。以下は、受け取った変数をaに代入することを意図した関数update_aを用いた例です。
a = 0
def update_a(val):
global a
a = val
update_a(1)
print(a) # きちんと 1 が出力される関数内にてglobal 変数名という形でglobal文を使用すると、関数内で指定した変数を使用した際にグローバル変数として扱うようになります。また、複数の変数を指定したい場合は、global a, b, c のようにカンマで区切ることで指定することができます。
よく混乱する例として、list等を代入せずに変更するケースがあります。例えば、以下のようなケースではglobal文は必要ありません。
li = []
def update_li(val):
li.append(val)
update_li(1)
print(li) # [1] と出力されるこれは、変数liは変更されてはいるものの代入されていないためです。global文が必要となるケースは、以下のように変数liに代入しているケースです。
li = []
def update_li(val):
global li
li = li + [val]
update_li(1)
print(li) # [1] と出力されるnonlocal
ここからは、global文についての補足となります。複雑なプログラムを書かない内は必要となることがないであろう知識なので、読み飛ばしても構いません。
for文の中にfor文を入れることができたのと同様に、Pythonでは関数内で関数を定義することが可能です。この際、以下のように関数内で用いたい外部の変数がグローバル変数でない場合が存在します。
def get_1():
value = 0
def set_1():
# ここで用いている value はグローバル変数ではないので、global は使えない
value = 1 # Error: local variable 'value' referenced before assignment
set_1()
return valueこのような場合に使用できる文として、nonlocal文が存在します。これを用いて上のコードを書き直すと、以下の通りとなります。
def get_1():
value = 0
def set_1():
nonlocal value
value = 1
set_1()
return value2.01.いろいろなfor文
リストのリスト
リストのリスト
リストを要素とするリストの場合などには、カンマ区切りで受け取ると複数の変数に一気に格納することができます。
L = [[5, 10], [6, 20], [7, 50]]
for a, b in L:
print("a は", a, "です。 b は", b, "です。")実行結果
a は 5 です。 b は 10 です。
a は 6 です。 b は 20 です。
a は 7 です。 b は 50 です。3 要素以上の場合
内側のリストが 3 要素以上になっても同様に書けますが、受け取る側の引数の個数が異なるとエラーになるので注意してください。
L = [[1, 2, 3], [4, 5, 6]]
for a, b, c in L:
print("a は", a, "です。 b は", b, "です。 c は", c, "です。")実行結果
a は 1 です。 b は 2 です。 c は 3 です。
a は 4 です。 b は 5 です。 c は 6 です。zip
複数のリストを同時に前からループ処理したい場合、 zip 関数が便利です。
A = [3, 4, 5, 6, 7]
B = [10, 20, 40, 80, 160]
# A と B から 1 つずつ要素を取得し a および b に格納する
for a, b in zip(A, B):
print(a, b)実行結果
3 10
4 20
5 40
6 80
7 160ふたつのリストの長さが異なる場合は短い方が終わるまで処理されます。
A = [3, 4, 5, 6, 7, 8, 9, 10]
B = [10, 20, 40, 80, 160]
# A と B から 1 つずつ要素を取得し a および b に格納する
for a, b in zip(A, B):
print(a, b)実行結果
3 10
4 20
5 40
6 80
7 160発展的な内容
イテラブルオブジェクト
本節では主にリストや文字列の要素を順に処理するループを紹介しましたが、より一般的には イテラブル(iterable) なオブジェクトに対して同様の処理を行うことができます。イテラブルなオブジェクトとは、要素を一つずつ順番に取り出すことができるオブジェクトのことです。 list、 tuple、 str、 set、 dict などがイテラブルオブジェクトに該当し、これらはfor文などで逐次的に処理できます。また本節では range を使う書き方はおまじないのように説明しましたが、 range もイテラブルオブジェクトのひとつです。
2.02.多重ループ
多重ループの break/continue
for 文や while 文には break や continue という命令がありました。多重ループはループ文の中にループ文を入れたものなので、通常の for 文と同様に break/continue 命令を使うことができます。
多重ループで break 命令を使うと 1 段階ループを抜けることができます。内側のループの中で break すると内側のループを抜けることができますが、この break によって外側のループを抜けることはできません。
多重ループを抜ける方法はいくつかありますが、そのうちのひとつとして「ループを抜けるかどうかを管理する変数(フラグ変数)を用意し、フラグ変数の値に応じてループを抜けるかどうか分岐する」という方法があります。
「i と j が両方 1 になったらループを抜ける」という処理を、フラグ変数を持つ方法で書くと以下のようになります。
# 外側のループを抜ける条件を満たしているかどうか(フラグ変数)
finished = False
for i in range(3):
for j in range(3):
print(i, j)
if i == 1 and j == 1:
print("i と j が両方 1 なので終了。")
finished = True
if finished:
break
if finished:
break実行結果
0 0
0 1
0 2
1 0
1 1
i と j が両方 1 なので終了。また、フラグ変数を持つ方法以外に、多重ループの部分を関数化し return を用いて抜ける方法もあります。
def func():
for i in range(3):
for j in range(3):
print(i, j)
if i == 1 and j == 1:
print("i と j が両方 1 なので終了。")
return
func()実行結果
0 0
0 1
0 2
1 0
1 1
i と j が両方 1 なので終了。2.03.内包表記
キーポイント
- (リスト内包表記)
[(変数を使った処理) for (変数名) in (変数を動かす範囲)]のように書くことで変数を使った処理の結果を要素に持ち、- 変数は for 文で指定の範囲を動く
リストを取得できる。
- (標準入力から数値リストを取得)
数値の列を標準入力から受け取ってリストにする処理は[int(item) for item in input.split()]として記述できる - (フィルタリング)
[(変数を使った処理) for (変数名) in (変数を動かす範囲) if (条件式)]のように書くことで
*変数を使った処理の結果を要素に持ち、 - 変数は for 文で指定の範囲を動くが、
*条件式が True の範囲のみに絞り込んだ
リストを取得できる。
リスト内包表記の例
# 例1. range(3) の要素それぞれに 1 を足す処理をする -> [1,2,3]
l = [hoge+1 for hoge in range(3)]
# 例2. l の要素それぞれに 2 倍する処理をする -> [2,4,6]
l2 = [2*i for i in l]
# 例3. l2 の要素それぞれに、「要素とそれから 1 を引いた値の2要素からなるリストを作る」処理をする -> [[2,1], [4,3], [6,5]]
l3 = [[val, val - 1] for val in l2]組み込み関数に渡す
1.12節で扱った組み込み関数に対し、内包表記で引数を与えることが可能です。
l = [-3, -1, 1, 2]
a = max(v*v for v in l)
b = min(v*v for v in l)
c = sum(v*v for v in l)
print(a,b,c)出力
9 1 15もちろん、a = max([v*v for v in l]) のようにリスト内包表記で作ったリストを関数に渡しても同じ結果になります。
この場合リストを作る処理が一度行われるため、計算速度・メモリ使用量が僅かではありますが大きくなります。
if 文によるフィルタリング
内包表記の for 文では直後に if 文をつなげて書くことが可能です。この場合、リストの要素は if 文の判定が真である要素のみに絞り込まれ(フィルタリングされ)ます。
ひとつ例を示します:
l = [3, 1, 4, 1, 5]
l_only_even = [v for v in l if v%2==0]
l_only_odd = [v for v in l if v%2==1]
print(l_only_even)
print(l_only_odd)出力
[4]
[3, 1, 1, 5](発展) 複雑な内包表記
二重ループを伴う内包表記
次の例は2つのリストが与えられたときに、それぞれから1つの要素を取るリストを要素に持つ二重リストを計算しています:
xs = [1, 2, 3]
ys = ["a", "b", "c"]
xys = []
for x in xs:
for y in ys:
xys.append([x,y])
print(xys)出力
[[1, 'a'], [1, 'b'], [1, 'c'], [2, 'a'], [2, 'b'], [2, 'c'], [3, 'a'], [3, 'b'], [3, 'c']]このコードは次のように内包表記で書き換えることが可能です。
xs = [1, 2, 3]
ys = ["a", "b", "c"]
xys = [[x,y] for x in xs for y in ys]
print(xys)ネストした内包表記
xs = [1, 2, 3]
ys = ["a", "b", "c"]
xys = [[[x,y] for x in xs] for y in ys]
print(xys)出力
[[[1, 'a'], [2, 'a'], [3, 'a']], [[1, 'b'], [2, 'b'], [3, 'b']], [[1, 'c'], [2, 'c'], [3, 'c']]]二重ループとフィルタリングとの組み合わせ
二重ループとフィルタリングの組み合わせの例を以下に示します:
xs = [1,2,3]
ys = [4,5,6]
# 和が3の倍数である (x,y) のリスト
xys_filter = [[x,y] for x in xs for y in ys if (x+y)%3==0]
print(xys_filter)出力
[[1, 5], [2, 4], [3, 6]]二重ループにフィルタリングも組み合わせると、慣れているプログラマにとっても読みづらくなるため、あまり推奨はしません。このような場合は通常の for 文で記述したほうが良いでしょう。
この例は次のようにすれば内包表記を使わずに記述することができます:
xys_filter2 = []
for x in xs:
for y in ys:
if (x+y)%3==0:
xys_filter2.append([x,y])2.04.多次元配列
キーポイント
- 二次元配列
aに対してlen(a)とすることでaの行数を、len(a[0])とすることでaの列数を取得できる [list(map(int, input().split())) for _ in range(N)]とすることで行数 N の二次元配列を入力から受け取ることができる[[0]*M for _ in range(N)]とすることですべての値が 0 のサイズ N×M の二次元配列を作ることができる
二次元配列
特に、「数値を要素に持つリスト」を要素として持つリストのことを二次元配列といいます。
a = [[1,3,5],[2,4,6]]この場合、リストの 0 番目の要素は [1,3,5] というリスト、1 番目の要素は [2,4,6] というリストになります。
print(a[0])
print(a[1])出力
[1, 3, 5]
[2, 4, 6]二次元配列を入力から取得する
競技プログラミングでは入力として二次元配列が与えられることがしばしばあります。
練習として、次のような入力が与えられる状況を考えます:
N M
A11 A12 ⋯ A1M
A21 A22 ⋯ A2M
⋮
AN1 AN2 ⋯ ANMこの入力から二次元配列を取得してみましょう。以下に3つの方法を示します:
方法 1
N, M = list(map(int, input().split()))
a = []
for i in range(N):
a.append(list(map(int, input().split())))方法 2
N, M = list(map(int, input().split()))
a = [None]*N
for i in range(N):
a[i] = list(map(int, input().split()))方法 3
N, M = list(map(int, input().split()))
a = [list(map(int, input().split())) for _ in range(N)]出力
[[1, 3, 5], [2, 4, 6]]要素がすべて 0 の二次元配列を作る
以下のように書くことでサイズ N×M の二次元配列を作ることができます:
N = 2
M = 3
a = [[0 for _ in range(M)] for _ in range(N)]
# a = [[0] * M for _ in range(N)] としてもよい
print(a)出力
[[0, 0, 0], [0, 0, 0]]二次元配列を作成する際の注意
行数と列数の指定方法の注意
サイズ N×M の二次元配列を作る際に、[[0 for _ in range(N)] for _ in range(M)] のように、N と M を逆にしてしまわないように気を付けてください。内包表記の動作から、最後の range の中に書いた数値が外側のリストのサイズになります。そのため、N を最後に書くことになります。
二次元配列の初期化方法の注意
サイズ N×M の二次元配列を初期化する際、次のように書いてしまわないように注意してください:
a = [[0] * M] * Nこのように書くと配列自体は作成できますが、いずれかのリストに対する変更が全てのリストに共有されるという不具合が生じてしまいます:
a = [[0] * 2] * 3
print("更新前:", a)
a[0][0] = 1
print("更新後:", a)出力
更新前: [[0, 0], [0, 0], [0, 0]]
更新後: [[1, 0], [1, 0], [1, 0]]上記のコードでは (0,0) 成分に 1 を代入したため、[[1, 0], [0, 0], [0, 0]] となることが期待されますが、出力を見ると配列の1列目の値がすべて 1 に変更されてしまっています。
この原因の詳細は「ポインタ」等の未解説の概念が必要になるため省略しますが、この記法では二次元配列内のリストがすべて同じ実体を共有するためこのようなことが起こってしまいます。
同様に、N×0 の二次元配列を作る際に以下のように書いてしまわないように注意してください:
N = 10
a = [[]] * Nこのように書くと、二次元配列内の空リストがすべて同じ実体を持つため、いずれかのリストに対する変更がすべてのリストに共有されてしまいます:
N = 10
a = [[]] * N
print("更新前:", a)
a[0].append(100)
print("更新後:", a)出力
更新前: [[], [], [], [], [], [], [], [], [], []]
更新後: [[100], [100], [100], [100], [100], [100], [100], [100], [100], [100]]多次元配列
二次元配列を拡張して、三次元、四次元… の配列を作ることも可能です。
次の例では三次元配列を内包表記によって初期化し、次に三重ループでその要素を書き換えています:
N = 2
M = 2
D = 2
lst3d = [[[0]*D for _ in range(M)] for _ in range(N)]
for i in range(N):
for j in range(M):
for k in range(D):
lst3d[i][j][k] = (i,j,k)
print(lst3d)出力
[[[(0, 0, 0), (0, 0, 1)], [(0, 1, 0), (0, 1, 1)]], [[(1, 0, 0), (1, 0, 1)], [(1, 1, 0), (1, 1, 1)]]]問題コード
n,m = map(int, input().split())
ab = [[int(x)-1 for x in input().split()] for _ in range(m)]
r = [["-"]*n for _ in range(n)]
for i in range(m):
r[ab[i][0]][ab[i][1]] = "o"
r[ab[i][1]][ab[i][0]] = "x"
for i in range(n):
print(*r[i])n,m = map(int, input().split())
ab = [[int(x)-1 for x in input().split()] for _ in range(m)]
r = [["-"]*n for _ in range(n)]
for a,b in ab:
r[a][b] = "o"
r[b][a] = "x"
for ri in r:
print(*ri)2.05.再帰関数
再帰関数の 3 つの部分
再帰関数は、以下の 3 つの部分に分けることができます。
- ベースケース : 簡単に答えが求められる小さいケースは、再帰呼び出しをせず直接答えを求める。
- 再帰呼び出し : 自身を呼び出して、1 つ小さなケースの答えを計算する。再帰呼び出しを繰り返すことで、必ずベースケースに到達することができる。
- 答えの計算 : 再帰呼び出しの結果を利用して、答えを計算する。
def sum_triangle(n):
if n == 0: # ベースケース
return 0
s = sum_triangle(n - 1) # 再帰呼び出し
return s + n # 答えの計算再帰関数の注意点
再帰深さの上限
Python では、後述するスタックオーバーフローを防ぐために再帰の深さに制限がかけられており、デフォルトでは、1000 回より多く関数呼び出しが連なると RecursionError が発生して RE になります。
再帰深さの上限を変更するには、sys.setrecursionlimit を実行します。
import sys
sys.setrecursionlimit(10 ** 6) # 再帰深さの上限を 1000000 回に変更する
def sum_triangle(n):
if n == 0:
return 0
s = sum_triangle(n - 1)
return s + n
print(sum_triangle(1000))出力
500500PyPy での再帰関数の最適化
PyPy は実行時にコンパイルを行なって処理を高速化しており、大抵の場合は CPython より高速ですが、関数呼び出しのインライン化(関数呼び出しを関数の中身に置き換えて関数呼び出しをなくすこと)に関わる処理と再帰関数の相性が悪く、PyPy で深い再帰を実行すると、CPython と比べて遅くなることがあります。
この場合には、再帰関数の実行前に pypyjit.set_param(inlining=0) を実行し、インライン化をしないように設定することで高速化することができます。
設定を元に戻すには pypyjit.set_param("default") を実行します。
詳しい情報は 公式ドキュメント を参照してください。
import pypyjit
def sum_triangle(n):
if n == 0:
return 0
s = sum_triangle(n - 1)
return s + n
pypyjit.set_param(inlining=0) # 以下のコードではインライン化を行わない
print(sum_triangle(1000))
pypyjit.set_param("default") # 以下のコードではインライン化を行うさらなる再帰関数の例
クイックソート
# 入力 : リスト a
# 出力 : a を昇順にソートしたリスト
def quick_sort(a):
# ベースケース : a が空であれば、出力は空のリストである
if len(a) == 0:
return []
# a から要素を 1 つ取り出して p とする
p = a.pop()
# a から p 未満の要素を集めたリストを lo, p 以上の要素を集めたリストを hi とする
lo = []
hi = []
for x in a:
if x < p:
lo.append(x)
else:
hi.append(x)
# 再帰呼び出し : lo と hi をソートする
lo = quick_sort(lo)
hi = quick_sort(hi)
# 答えの計算 : lo と p と hi をこの順に並べたものが a の昇順ソートである
return lo + [p] + hi2.06.計算量
計算量
時間計算量
「プログラムの計算のステップ数が入力に対してどのように変化するか」という指標を時間計算量といいます。計算のステップ数とは、四則演算や数値の比較などの単純な演算の回数です。
空間計算量
「プログラムが使用するメモリの量が入力に対してどのように変化するか」という指標を空間計算量といいます。メモリとはコンピュータの記憶領域のことを指し、変数を使用した分だけメモリを消費します。また、文字列や配列などは内部の要素数等に応じてメモリを消費します。
計算量の例
次のプログラムは 1 から N までの総和 (1+2+3+⋯+N) をループを用いて計算するものです。
N = int(input())
s = 0
for i in range(1, N + 1):
s += i
print(s)このプログラムでは for 文で N 回の繰り返し処理を行っているので、計算ステップ数は入力の N の大小に応じて変わります。N 回の繰り返しを行うので、計算ステップ数はおおよそ N 回になります。このときの時間計算量は次で紹介するオーダー記法を用いて O(N) と表します。
このプログラムで使用している変数は、入力の N の大小に関わらず N と s と i の 3 つです。 このときの空間計算量はオーダー記法を用いて O(1) と表します。
O(logN)
以下の図を見てください。長さ 8 の棒を長さが 1 になるまで半分に切る(2 で割る)ことを繰り返したときに切る回数は log28=3 回です。
このように計算量に出てくる log は「半分にする回数」を表すことが多いです。
logN は N に対して非常に小さくなるので、計算量の中に O(logN) が出てきた場合でも実行時間にそこまで影響しないことが多いです。
オーダー記法では log の底( log28 の 2 の部分)は省略して書かれることが多いです。
なぜなら、log の底の違いは定数倍の違いだけとみなすことができ、オーダー記法では定数倍は省略するからです。
計算量のおおまかな大小
| N | O(1) | O(logN) | O(N) | O(NlogN) | O(N^2) | O(2^N) |
|---|---|---|---|---|---|---|
| 1 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 |
| 10 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 |
| 1,000 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 0.01 秒くらい | 地球爆発 |
| 10^6 | 一瞬 | 一瞬 | 0.01 秒くらい | 0.2 秒くらい | 3 時間くらい | 地球爆発 |
| 10^8 | 一瞬 | 一瞬 | 1 秒くらい | 30 秒くらい | 3 年くらい | 地球爆発 |
| 10^16 | 一瞬 | 一瞬 | 3 年くらい | 170 年くらい | 地球爆発 | 地球爆発 |
組み込み関数の計算量
| 関数 | 計算量(引数のリスト等の長さを N とする) |
|---|---|
len | O(1)(以下に補足あり) |
sum | O(N) |
sorted | O(NlogN) |
3.01.Pythonで使える機能の整理
組み込みで定義されている機能の一覧は公式ドキュメントを参照するのがよいでしょう。
3.02.組み込みコンテナ
list / tuple
データの列を扱うことのできるデータ構造
list/tupleの主要な操作
| 操作 | 記法 | 計算量 | list | tuple |
|---|---|---|---|---|
| 値のアクセス | l[i] | O(1) | ○ | ○ |
| 値の変更 | l[i] = x | O(1) | ○ | |
| 末尾への値の挿入 | l.append(x) | O(1) | ○ | |
| 末尾以外への値の挿入 | l.insert(i, x) | O(N) | ○ | |
| 末尾の値の削除 | l.pop() | O(1) | ○ | |
| 末尾以外の値の削除 | l.pop(i) | O(N) | ○ | |
| 列の長さの取得 | len(l) | O(1) | ○ | ○ |
| 値の存在判定 | x in l | O(N) | ○ | ○ |
| 値の出現回数 | l.count(x) | O(N) | ○ | ○ |
set
集合を扱うことのできるデータ構造
setの主要な操作
| 操作 | 記法 | 計算量 1 |
|---|---|---|
| 値の追加 | s.add(x) | O(1) |
| 値の削除 | s.remove(x) | O(1) |
| 集合の要素数の取得 | len(s) | O(1) |
| 値の存在判定 | x in s | O(1) |
dict
辞書や連想配列と呼ばれるデータ構造
dictの主要な操作
| 操作 | 記法 | 計算量 1 |
|---|---|---|
| 値のアクセス | d[k] | O(1) |
| 値の追加・更新 | d[k] = v | O(1) |
| キーの削除 | d.pop(k) | O(1) |
| 辞書の項目数 | len(d) | O(1) |
| キーの存在判定 | k in d | O(1) |
tuple
tuple も list と同様にデータの列を扱うデータ構造です。list との最大の違いは、(文字列 (str) などと同様に)変更ができないことです。
ただ、あくまで tuple の中身の変更ができないだけで、その変数に代入されている tuple 自体を別のものに変更することはできます。
tuple を作る
# tuple (3, 1, 4, 1, 5) を作り、t に代入する
t = (3, 1, 4, 1, 5)
# いろいろな型を持つデータを 1 つの tuple に入れることができる
t = ("Hello", "AtCoder", 123, 4.5, [])
# 括弧は省略することもできる
t = "Hello", "AtCoder", 123, 4.5, []
# tuple (0, 1, 2, 3, 4) を作る
t = tuple(range(5))
# tuple (0, 1, 4, 9, 16) を作る
t = tuple(i * i for i in range(5))1 要素の tuple
- 1 要素の
tupleを作るときは、ただ括弧でくくっているだけと区別するため、明示的にカンマをつける必要があります。
t = (3) # カンマをつけないとただ括弧でかこっているだけとされてしまい tuple にならない
print(type(t)) # <class 'int'>
t = (3,) # 1 要素の tuple を作るときは明示的に最後のカンマをつける必要がある
print(type(t)) # <class 'tuple'>
t = 3, # 1 要素の tuple を作るときでも括弧は省略することもできる
print(type(t)) # <class 'tuple'>内包表記での初期化
- 内包表記で tuple を初期化するとき、
()でくくるだけだとgeneratorという別のものを作る記法になってしまうため、tuple()でくくる必要があります。
t = [i for i in range(5)] # list ならこの書き方で OK
print(type(t)) # <class 'list'>
t = (i for i in range(5)) # 上と同じように括弧だけ変えると tuple にならない
print(type(t)) # <class 'generator'>
t = tuple(i for i in range(5)) # 内包表記で tuple を作るにはこのように書く必要がある
print(type(t)) # <class 'tuple'>出力する
tuplet に対し、print(*t)で t の要素を空白区切りで出力できます。
tuple のさらなる機能
packing, unpacking
tuple は、複数の値をひとつの変数に格納していると見ることもできますが、逆に tuple の各要素を別々の変数に格納することもできます。これを、それぞれ packing, unpacking と呼びます。
# 複数の値をひとつの変数に代入 (packing)
t = 3, 1, 4, 1, 5
# tuple の各要素を別々の変数に代入 (unpacking)
a, b, c, d, e = t
# これも OK
a, b, c, d, e = (3, 1, 4, 1, 5)
# もちろんこれも OK
a, b, c, d, e = 3, 1, 4, 1, 5なので、1.04.変数と型 – 複数の変数への代入 で紹介した x, y = 2, 3 というコードは、(2, 3) という tuple を作り、それを x と y に unpacking していたということになります。
また、x, y = y, x についても同様です。
なお、特に unpacking については list などの他のコンテナでも同様に行えます。
set
set はデータの集合を扱うデータ構造です。集合とは、 重複する要素をもたない、順序づけられていない 要素の集まりです。
Python では、データに対し「ハッシュ値」というものを定義することで集合を扱うデータ構造を実現しています(set を使う上で、基本的には「ハッシュ値」の仕組みについて理解する必要はありません)。
set のメリット
- 追加・削除・存在判定などの操作が高速に行える
set のデメリット
- 同じ要素を複数格納することができない
- 順序を保持することができない
- つまり「i 番目に追加した要素を求める」といったことは基本的にはできない
- また、「i 番目に大きい要素を求める」といったこともできない
set を作る
set()で空のsetを作ることができます。{}だと空のdictになってしまうことに注意してください(dictについてはこの次に説明します)。
{ 要素1, 要素2, 要素3, ... }でsetを作ることができます。set( for 文に入れられるもの )でsetを作ることができます。set([1, 2, 3, 4, 5])などといったように、listからsetを作ることもできます。
{ 内包表記 }でsetを作ることができます。
for 文で要素を列挙する
sets に対し、for x in sで s の要素をひとつずつ x に代入して繰り返し処理を行うことができます。- このとき、要素の列挙される順序は、追加された順や小さい順とは限らないことに注意してください。
set の注意点
list は set に入れられない
setの要素にはlistを含めることはできません。- これは、
listは整数やstr,tupleなどと違い中身を変更できてしまうからです。 setは中で「ハッシュ値」という値を用いて検索しています。中身が勝手に変わるとこの検索方法が使えないので、Python では「listにはハッシュを定義しない」=「setに入れられない」としています。
- これは、
set を使ったテクニック
list の重複を除去する
- ある
listを一度setに変換してからもう一度listに変換すると、重複が除去できます。- ただし、順序はバラバラになります。
- 特に、
listl の重複を除去しつつソートしたいときはsorted(set(l))などと書くことができます。
l = [30, 10, 40, 10, 50]
# 重複を除去しつつソートする
l = sorted(set(l))
print(l) # [10, 30, 40, 50]dict
dict は連想配列や辞書と呼ばれるデータ構造です。dict を用いると、「要素 (key) に値 (value) が紐づいている」といったようなデータを簡単に扱うことができます。set と同様、Python では、要素 (key) に対し「ハッシュ値」というものを定義することで連想配列を実現しています(なので、set と同様、key に list を用いることはできません)。
dict を作る
{}で空のdictを作ることができます。{ key_1: value_1, key_2: value_2, ... }でdictを作ることができます。
# 同じキーがある場合、より後ろに書かれたものが格納される
d = {"Alice": 100, "Bob": 89, "Charlie": 95, "Alice": -1}
print(d) # {'Alice': -1, 'Bob': 89, 'Charlie': 95}また、内包表記でも { k: v for ... } という形で書くことで dict を作ることができます
square_root = {i * i: i for i in range(5)}
print(square_root) # {0: 0, 1: 1, 4: 2, 9: 3, 16: 4}要素の取得・追加・更新・削除・キーの存在判定
また、値が存在しないときに初期化をしてくれる defaultdict というものもあり、これを使用すると存在するかどうかの条件分岐を省略することもできます。defaultdict については 4 章で詳しく説明します。
dict を使う場合
l = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3]
counter = {}
for x in l:
# counter に要素 x が存在しない状態で counter[x] += 1 とするとエラーになるので、
# if 文で判定し、あらかじめ代入しておく
if x not in counter:
counter[x] = 0
counter[x] += 1
for k, v in counter.items():
print(k, v)defaultdict を使う場合
from collections import defaultdict
l = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3]
counter = defaultdict(int)
for x in l:
# defaultdict の場合エラーにならないので条件分岐が不要
counter[x] += 1
for k, v in counter.items():
print(k, v)for 文で要素を列挙する
dictd に対し、for k in d(またはfor k in d.keys())で d のキーを追加された順に k に代入して繰り返し処理を行うことができます。dictd に対し、for v in d.values()で d の値を追加された順に v に代入して繰り返し処理を行うことができます。dictd に対し、for k, v in d.items()で d のキーと値を追加された順にそれぞれ k,v に代入して繰り返し処理を行うことができます。
問題コード(最頻値)
from collections import defaultdict
n = int(input())
a = [int(x) for x in input().split()]
counter = defaultdict(int)
for ai in a:
counter[ai] += 1
max_k,max_v = -1, -1
for k,v in counter.items():
if max_v < v:
max_k,max_v = k,v
print(max_k,max_v)こうすれば配列の数が最小限になるんだ
じゃあDPとかも初期化いらないのか?
3.03.format と f 文字列
f-string とは
f-string は、変数等を埋め込んだ文字列を作成する際に便利な機能です。
例を見てみましょう。以下のコードは、Hello, Takahashi! と出力します。
name = "Takahashi"
print(f"Hello, {name}!")できること・使いどころ
ここでは競技プログラミングにおいてよく使われる例をいくつか紹介します。ここで紹介するもの以外の詳細は公式ドキュメントを参照してください。
小数点以下の桁数を指定した出力
浮動小数点数を出力する際、小数点以下の桁数を指定することができます。出力される値は、その1つ下の桁で四捨五入1されたものになります。
val = 3.1415
# 小数点以下2桁
print(f"{val:.2f}") # 出力: 3.14
# 小数点以下3桁
print(f"{val:.3f}") # 出力: 3.142
# 小数点以下8桁
print(f"{val:.8f}") # 出力: 3.14150000数値の10進法以外での出力
2進法、8進法、16進法で出力することができます。
value = 29
# 2進法
print(f"{value:b}") # 出力: 11101
# 8進法
print(f"{value:o}") # 出力: 35
# 16進法
print(f"{value:x}") # 出力: 1dチートシート表
| やりたいこと | 記述例 |
|---|---|
| 小数点以下の桁数を指定 | f"{val:.13f}" |
| 指数形式にする | f"{val:e}" |
| 2進法にする | f"{val:b}" |
| 16進法にする | f"{val:x}" |
| leading zeroを含て桁数を指定 | f"{val:013}" |
値が負でないとき先頭に + をつける | f"{val:+}" |
| パーセンテージにする | f"{val:%}" |
| 3桁ごとにカンマで区切る | f"{val:,}" |
| 指定した幅に右詰め | f"{val:>13}" |
| 指定した幅に左詰め | f"{val:<13}" |
3.04.ビット演算
負の数のビットシフト
a << b や a >> b の b が負のときはRuntime Errorになります。 a が負のとき、左シフト a << b は非負の場合と同様、 a * (2 ** b) と等価になります。右シフト a >> b は a // (2 ** b) と等価になります。整数除算の丸めはマイナス方向(負の数の場合は絶対値が大きくなる方向)に丸められる点に注意してください。
print(-3 << 2) # -12
print(-13 >> 2) # -4以下のコードはいずれもRuntime Error(negative shift count)になります。
print(1 << -1) # Runtime Error
print(1 >> -1) # Runtime ErrorビットごとのNOT演算(~)
この演算はややトリッキーであり、実用上も他の演算子で代用できるので、初学者は必ずしも履修する必要はありません。
整数 x に対するビット毎のNOT演算 ~x は、 -(x+1) と等価です。これは仮想的な無限長の2の補数表現を前提にビット毎に反転を行っていると解釈することもできます。負の数のビット表現を前提にしていることから、AND・OR・XORに比べて直感的に理解しづらいかもしれません。
なおこの演算は2回行うと元の整数に戻ります( ~~x = x ) 2 。
print(~6) # -7
print(~-7) # 6
print(~~100) # 100高速化
ビット演算では1回の演算で複数のビットについての計算をまとめて行うことができるので、この性質をうまく活かすとプログラムを高速化できることがあります。
最下位ビット
整数 x を2進法表記したときの、ゼロでない最も小さいビットは x & (-x) で取得することができます。
x = 12
print(x & (-x)) # 4
x = 99
print(x & (-x)) # 1演算子の優先順位
主要な演算子の優先順位を以下に示します。上ほど優先度が高いです。
| 演算子 | 説明 |
|---|---|
** | べき乗 |
+x, -x, ~x | 単項演算子 |
*, /, //, % | 乗除算、整数除算、剰余算 |
+, - | 加減算 |
<<, >> | ビットシフト |
& | ビット毎のAND |
^ | ビット毎のXOR |
\\ | ビット毎のOR |
<, <=, >, >=, !=, == | 比較演算子 |
not x | 否定 |
and | 論理積(かつ) |
or | 論理和(または) |
ビット全探索
N = 3
for i in range(1 << N):
L = []
for j in range(N):
if (i >> j) & 1: # 下から j 桁目のビットが立っている場合
L.append(j)
print(i, L)実行結果
0 []
1 [0]
2 [1]
3 [0, 1]
4 [2]
5 [0, 2]
6 [1, 2]
7 [0, 1, 2]3.05.発展的な文法
三項演算子
X if (条件式) else Y と書くことで、条件式の値が True であれば X 、そうでなければ Y を値にとる式を書くことができます。
次のプログラムでは、「i が偶数なら i そのもの、そうでなければ(奇数なら) i を 100 倍したもの」という式を三項演算子で記述しています1。
l = [(i if i%2==0 else i*100) for i in range(10)]
print(l)実行結果
[0, 100, 2, 300, 4, 500, 6, 700, 8, 900]論理演算の処理内容
1.07 節では論理演算子 and と or を扱いました。本節では知っておくと役に立つ、これらの演算の細かい処理内容を説明します。
これらの演算では左から順に与えられた式を評価していき、最終的な結果を返します。このとき、必ずしもすべての式を評価するとは限りません。例えば、A and B の演算において A が False となった場合、B の値によらず式全体の値も False であることが確定します。このような場合、B の評価は行われません。同様に、X or Y の演算において X が True となった場合、Y の値によらず式全体の値も True であることが確定します。この場合も Y の評価は行われません。
このように、不要な評価をスキップして式全体の値を評価を行うことを「短絡評価」と呼びます。
以上をまとめると、次のようになります:
and演算子の左側の式がFalseの場合、右側の式の評価は行われない。or演算子の左側の式がTrueの場合、右側の式の評価は行われない。
例えば次のコードでは2つある if 文のいずれにおいても短絡評価が行われた結果、hello 関数の呼び出しは行われません:
def hello():
print("Hello")
return True
if True or hello():
print("条件式はTrue")
if False and hello():
print("条件式はFalse")実行結果
条件式はTrueラムダ式
1.13 節では関数定義は以下のように記述することを学びました:
def 関数名(引数):
処理内容
return 返り値このとき、「処理内容」が存在しない関数であれば、実はこの記述は次のように一行で記述することが可能です。この記法を「ラムダ式」と呼びます:
関数名 = lambda 引数: 返り値例で確認してみましょう。次の func1 と func2 は全く同じように動作します:
def func1(a):
return a+10
func2 = lambda a: a+10
print(func1(1), func2(1))実行結果
11 11関数引数のデフォルト値
関数の定義 def 関数名(引数名): において、def 関数名(引数名 = デフォルト値) とすることで、引数を省略したときに デフォルト値 が使われるようになります。
3.06.いろいろなソート
評価指標を与えてソート
要素の値そのものではなく、何らかの評価指標があり、それを基準としてソートをしたいときがしばしばあります。
例として、「整数値のリストを、各値の下1桁でソートする」という問題を考えましょう:
l = [2, 6, 11, 100]
# 何らかの処理を行って [100, 11, 2, 6] を得たい方法1: 評価値と元の要素からなるタプルのリストをソートする
一つ目の方法は、先ほど説明した「タプルのソート」を活用します。
- 評価したい値と元の要素を並べたタプルのリストを作る
- そのリストをソートする
- 得られたリストから元の要素を抜き出す
という順で処理します。
「整数の下一桁の値」は「整数を10で割ったあまり」によって得られることに注意してください。
以下がコード例になります:
l = [2, 6, 11, 100]
l2 = [(v%10, v) for v in l] # (要素の下一桁, 要素) のリスト
print(l2) # [(2, 2), (6, 6), (1, 11), (0, 100)]
l2.sort()
print(l2) # [(0, 100), (1, 11), (2, 2), (6, 6)]
l = [item[1] for item in l2] # l2 の各要素から元の要素を抜き出す
print(l) # [100, 11, 2, 6]方法2: ソートの引数に評価値を与える関数を渡す
ソートの関数は引数 key として関数を渡すことができます。この場合、各要素を関数の返り値が昇順になるようにソートが行われます。
今回の場合、以下のような手順になります。
- 評価値(ここでは数値の下1桁 = 10 で割ったあまり)を計算する関数を実装
- その関数を
key引数として渡してソートを行う
以下のような実装例になります:
l = [2, 6, 11, 100]
def func(x):
return x % 10
l.sort(key = func)
print(l) # [100, 11, 2, 6]
# これは次のように 1 行で記述することも可能:
# l.sort(key = lambda x: x%10)最後のコメントにあるように、前述のラムダ式を使うことで関数の名称をつけることなく評価指標を与えることも可能です。このようなラムダ式の使い方は競技プログラミングでしばしば出てくるので覚えておくとよいでしょう。
なお、引数 key は sorted 関数を用いる場合も同様に利用することができます。
この「方法2」に慣れるためにいくつかの例を出します。
# x の降順にソート : reverse 引数を使わずに以下のように書くことも可能 l = [2, 6, 11, 100] print(sorted(l, key = lambda x: -x)) # [100, 11, 6, 2] # タプルの2番目の要素でソート l = [(3,1), (4,2), (0,1)] print(sorted(l, key = lambda x: x[1])) # [(3, 1), (0, 1), (4, 2)]
3. 競技プログラミングをやる
2.2で基本的な入力・出力形式は覚えたので、後は実際に書いて慣れていきます。
プラットフォームとしては、AtCoderやAizuOnlineJudge、Paizaスキルチェックなどがあります。
この中ではPaizaスキルチェックが色々都合がよかったのでそれにしました。
- 問題が難しすぎない(数学的考察は必要ない)
- 問題文・提出ページ・コードテストが1ページで完結している
- 問題を解くことでレートが上がる
なおレートが上がるのは欠点でもあり、自分はまだ正答率が100%なので若干プレッシャーでもありました。
そういう場合は他のプラットフォームが良いかもしれませんね。
おわりに
今回は自分がPythonを勉強した内容をまとめました。
投稿者プロフィール
最新の投稿
 【AI】2025年12月26日RAG改良手法の学習
【AI】2025年12月26日RAG改良手法の学習 Python2025年12月25日StreamlitでRAGを作ってみた
Python2025年12月25日StreamlitでRAGを作ってみた Python2025年12月23日Pythonを学習するにあたってやったこと
Python2025年12月23日Pythonを学習するにあたってやったこと- 未分類2025年11月28日『Webを支える技術』を読んだ学び















